

The rapid evolution of artificial intelligence has created an insatiable demand for computational power, particularly for training large-scale models. Traditionally, this need has been met by centralized data centers owned by hyperscalers and cloud giants. However, a new paradigm is emerging: decentralized GPU networks. By distributing compute tasks across global pools of underutilized GPUs, these networks are redefining how AI model training is scaled, accessed, and financed.


Why Decentralized GPU Networks Are Gaining Momentum
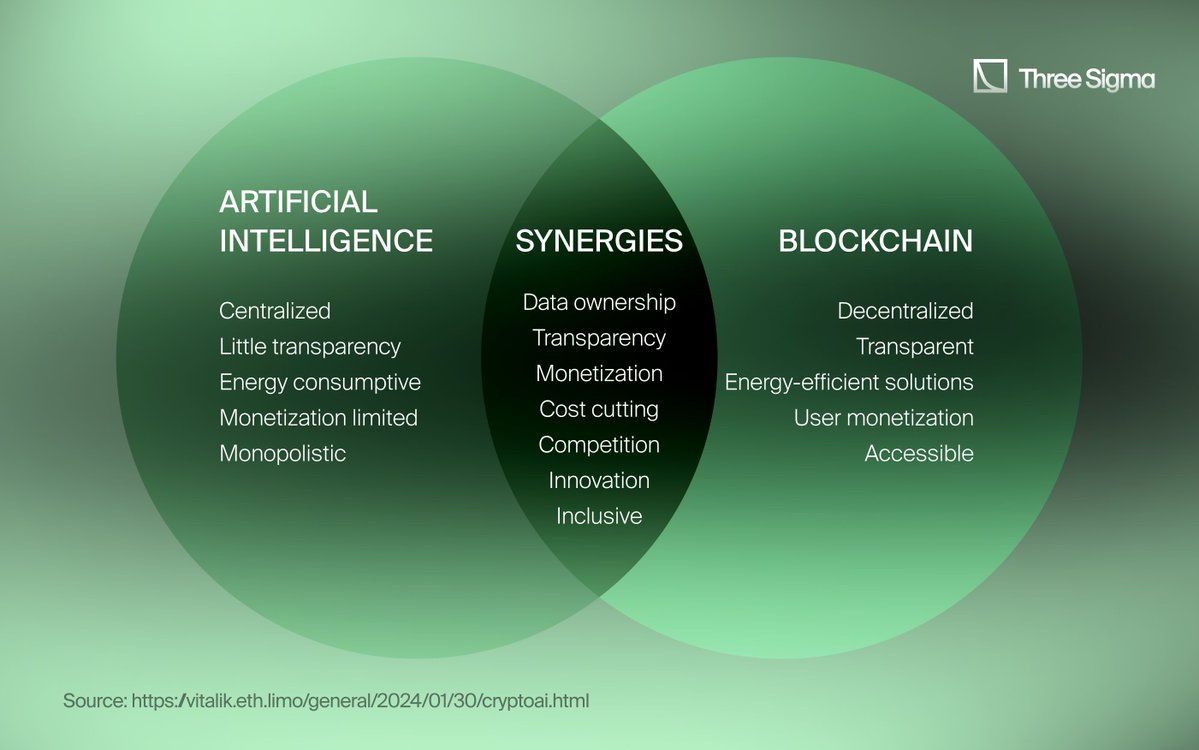
Centralized infrastructure comes with inherent bottlenecks: high costs, limited accessibility for smaller players, and single points of failure. In contrast, decentralized AI compute networks tap into the idle capacity of thousands of GPUs worldwide. This approach not only slashes expenses but also democratizes access to enterprise-grade hardware once reserved for tech behemoths.
Consider the cost efficiency seen on platforms like Nosana, where developers leverage decentralized GPU power for both training and inference at a fraction of traditional cloud prices. The ability to scale resources dynamically is another game-changer. For instance, Swarm’s Decentralized Learning Machine (DLM) enables users to spin up clusters of up to 512 DLMs optimized for AI workloads, no need for massive upfront investments or long-term contracts (source).
Top Advantages of Decentralized GPU Networks for AI Training
-
Cost Efficiency: Decentralized GPU networks like Akash Network and io.net leverage idle global GPU resources, offering AI model training at up to 70% lower cost compared to traditional cloud providers.
-

Scalability: Platforms such as Swarm DLM and Planck Network enable dynamic scaling by aggregating thousands of GPUs, allowing rapid expansion to meet demanding AI workloads.
-

Accessibility: Services like AlphaNeural AI and Nous Network democratize access to high-performance computing, empowering individuals and smaller organizations to train advanced AI models without major infrastructure investments.
-
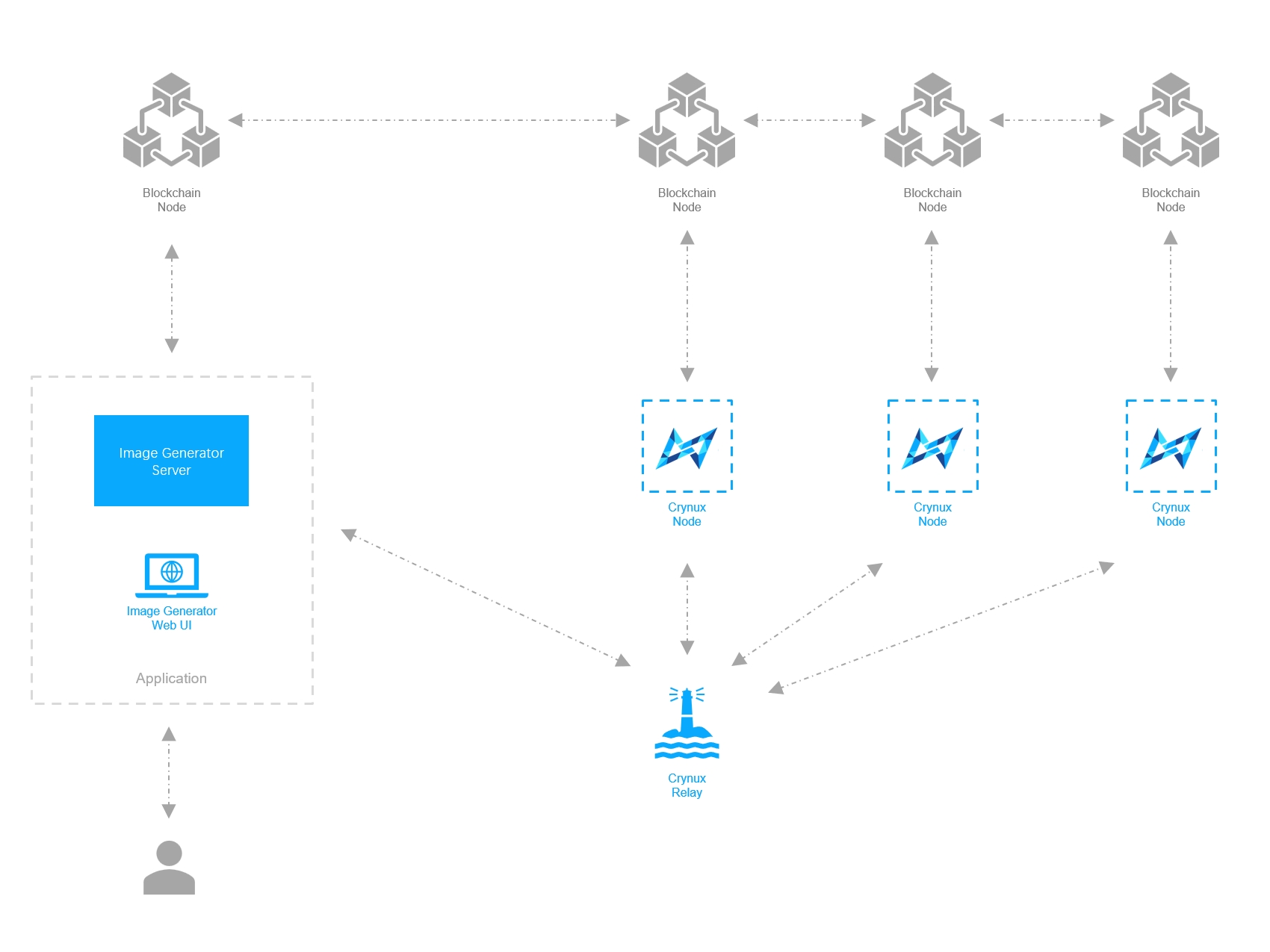
Fault Tolerance and Resilience: Decentralized frameworks, including Decentralized Diffusion Models, distribute training across independent clusters, reducing the risk of downtime from localized GPU failures and enhancing overall system robustness.
-

Support for Diverse Hardware: Solutions like the ATOM Framework and TensorWave‘s AMD GPU clusters enable asynchronous training across a wide range of hardware, from consumer GPUs to enterprise-grade accelerators, optimizing resource utilization.
Crypto-Powered Incentives and Blockchain Compute Infrastructure
The engine behind these decentralized systems is not just technical, it’s economic. Crypto-powered incentives ensure that individuals are motivated to contribute their hardware while maintaining network security and reliability. Projects like Nous and Prime Intellect are pioneering this approach by integrating blockchain-based rewards with open AI training (source).
This convergence of blockchain compute infrastructure with distributed AI is creating entirely new markets. Platforms such as Akash Network present themselves as the “Decentralized Cloud Built for AI’s Next Frontier, ” offering global GPU power at substantially lower costs and even providing up to $500 in GPU credits to jumpstart adoption.
Real-World Deployments: From Bare Metal to Massive Clusters
The vision is not just theoretical, it’s already being realized at scale. In July 2025, TensorWave unveiled North America’s largest AMD GPU-based cluster dedicated to AI model training, boasting 8,192 MI325X accelerators cooled by direct liquid systems. This deployment demonstrates how decentralized approaches can rival or even surpass traditional data centers in both performance and efficiency (source).
Other notable implementations include AlphaNeural AI’s marketplace connecting users with a worldwide network of GPU providers (source). These platforms allow anyone, from solo researchers to startups, to deploy advanced models without owning any physical hardware.
Pushing the Boundaries: Research and Emerging Frameworks
The technical landscape is advancing rapidly as well. Researchers have introduced frameworks like Decentralized Diffusion Models, which distribute model training across independent clusters or data centers. This reduces reliance on high-bandwidth centralized networking while boosting resilience against local failures (source). Meanwhile, the ATOM framework enables asynchronous training across heterogeneous peers, including consumer-grade GPUs, optimizing throughput beyond what pipeline parallelism can achieve (source).
These emerging frameworks are not just incremental improvements, they represent a fundamental shift in how AI model training can be orchestrated at scale. By decoupling compute from centralized data silos and leveraging adaptive techniques, decentralized GPU networks make it possible to train larger, more complex models with superior fault tolerance and resource utilization.
Yet, the journey toward fully decentralized AI compute is not without its hurdles. Data privacy remains a top concern, especially when sensitive datasets traverse global networks of independent nodes. Hardware heterogeneity introduces additional complexity: not all GPUs are created equal, and ensuring consistent performance across disparate hardware requires sophisticated orchestration. Communication overhead between distributed nodes can also impact efficiency, particularly for massive models that demand frequent parameter synchronization.
To address these obstacles, ongoing research is innovating on several fronts. Adaptive compression algorithms are being developed to minimize bandwidth requirements while preserving training accuracy. Blockchain-based sharding frameworks offer promising solutions for secure data partitioning and provenance tracking, critical for trustless collaboration in open networks (source).
The Road Ahead: Democratizing AI Development
The implications of these advancements extend far beyond cost savings or technical novelty. As decentralized GPU networks mature, they have the potential to reshape the competitive landscape in artificial intelligence:
How Decentralized GPU Networks Transform AI Training
-
Cost Efficiency with Decentralized Marketplaces: Platforms like Akash Network and io.net enable AI developers to access global GPU resources at a fraction of traditional cloud costs, leveraging idle hardware and reducing expenses by up to 70%.
-

Dynamic Scalability for Large AI Workloads: Solutions such as Swarm’s Decentralized Learning Machine (DLM) allow users to spin up high-performance GPU clusters on demand, supporting rapid scaling for training complex AI models.
-

Democratized Access to High-Performance Computing: Decentralized networks like AlphaNeural AI and Nous Network open advanced AI training to individuals and smaller organizations, removing the barrier of costly infrastructure investment.
-
Innovative Distributed Training Frameworks: Research-backed systems such as Decentralized Diffusion Models and the ATOM Framework enable asynchronous, resilient training across global clusters, improving efficiency and fault tolerance.
-

Enterprise-Grade Deployments at Scale: TensorWave‘s deployment of North America’s largest AMD GPU-based AI cluster, featuring 8,192 MI325X accelerators, demonstrates how decentralized networks can support exascale AI workloads with advanced cooling and throughput.
-
Enhanced Security and Privacy via Blockchain: Projects like Planck Network and Templar Protocol integrate blockchain for secure, auditable, and privacy-preserving AI model training across distributed GPU resources.
First, access to scalable compute will no longer be limited to well-funded corporations or academic institutions. Open-source communities, independent researchers, and emerging markets can participate on equal footing, accelerating innovation across domains from language models to generative art.
Second, new business models are emerging at the intersection of crypto-powered incentives and blockchain compute infrastructure. By aligning economic rewards with network participation and contribution quality, projects like Akash Network and Planck Network are fostering robust ecosystems where value flows transparently between hardware providers and AI developers.
“Decentralized GPU power is not just about cheaper compute, it’s about unlocking creativity at a global scale. “
This democratization also brings new responsibilities. Governance mechanisms must evolve to balance openness with security; standards will be needed for interoperability across diverse platforms; incentives must be continually refined to prevent exploitation or resource hoarding.
The Strategic Edge for Builders and Investors
For those building or investing in the future of AI infrastructure, understanding the nuances of decentralized GPU networks is now mission-critical. Early adopters stand to benefit from lower operational costs, greater flexibility in scaling workloads, and direct participation in emerging token economies tied to computational resources.
The race is on, not just for faster models but for more inclusive and resilient foundations powering tomorrow’s breakthroughs. As technical barriers fall and adoption accelerates, decentralized AI compute will become a cornerstone for scalable innovation across industries.




