

Centralized AI infrastructure has long been the default for deploying large language model (LLM) inference at scale, but this approach is increasingly untenable. The costs of running LLMs through cloud giants, driven by expensive, specialized GPU clusters and rigid vendor pricing, have kept advanced AI out of reach for many startups and researchers. However, a new paradigm is emerging: decentralized LLM inference networks are slashing compute costs by up to 70%, creating a tipping point for the economics of AI deployment.


Leveraging Idle GPUs: The Engine Behind Cost Reduction
The core innovation driving these savings is the ability to harness underutilized GPU resources scattered around the world. Platforms like Hyperbolic aggregate idle GPUs into a unified, decentralized compute fabric. Instead of relying solely on hyperscale data centers, these networks tap into everything from consumer gaming rigs to enterprise-grade accelerators. The result? High-performance LLM inference at a fraction of traditional prices, Hyperbolic reports cost reductions as high as 75% compared to conventional providers (source).
This distributed approach not only democratizes access to AI infrastructure but also creates new incentive models, participants can earn rewards by contributing their idle hardware, aligning with the broader DePIN (Decentralized Physical Infrastructure Networks) movement.
Architectural Innovations: Attention Offloading and Phase Splitting
Cost savings are not just about raw resource aggregation, they also stem from smarter architectural choices in how inference workloads are distributed. Recent breakthroughs include:
Key Innovations Driving Decentralized LLM Inference Efficiency
-
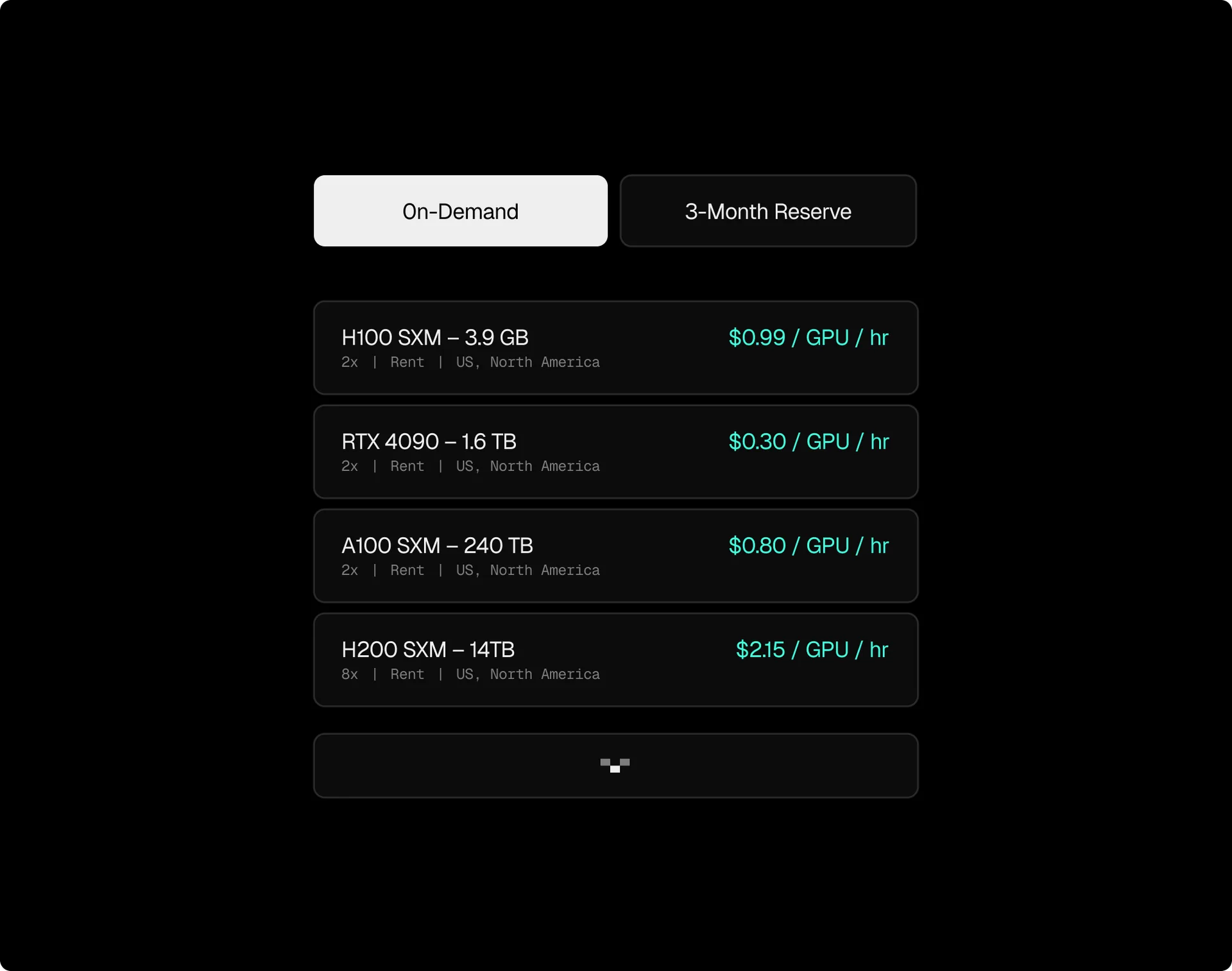
Leveraging Underutilized GPU Resources via Hyperbolic: Platforms like Hyperbolic aggregate idle GPUs from a global network, enabling high-performance LLM inference at up to 75% lower cost than centralized providers. This democratizes access to AI by drastically reducing infrastructure expenses for startups and researchers.
-

Attention Offloading and Phase Splitting with Lamina and Splitwise: Lamina distributes LLM inference tasks by offloading attention computations to consumer GPUs, reserving high-end accelerators for other operations. This yields up to 12.1x higher throughput per cost. The Splitwise technique further boosts efficiency by dividing inference into prompt computation and token generation phases, optimizing hardware use and achieving 1.4x higher throughput at 20% lower cost.
-
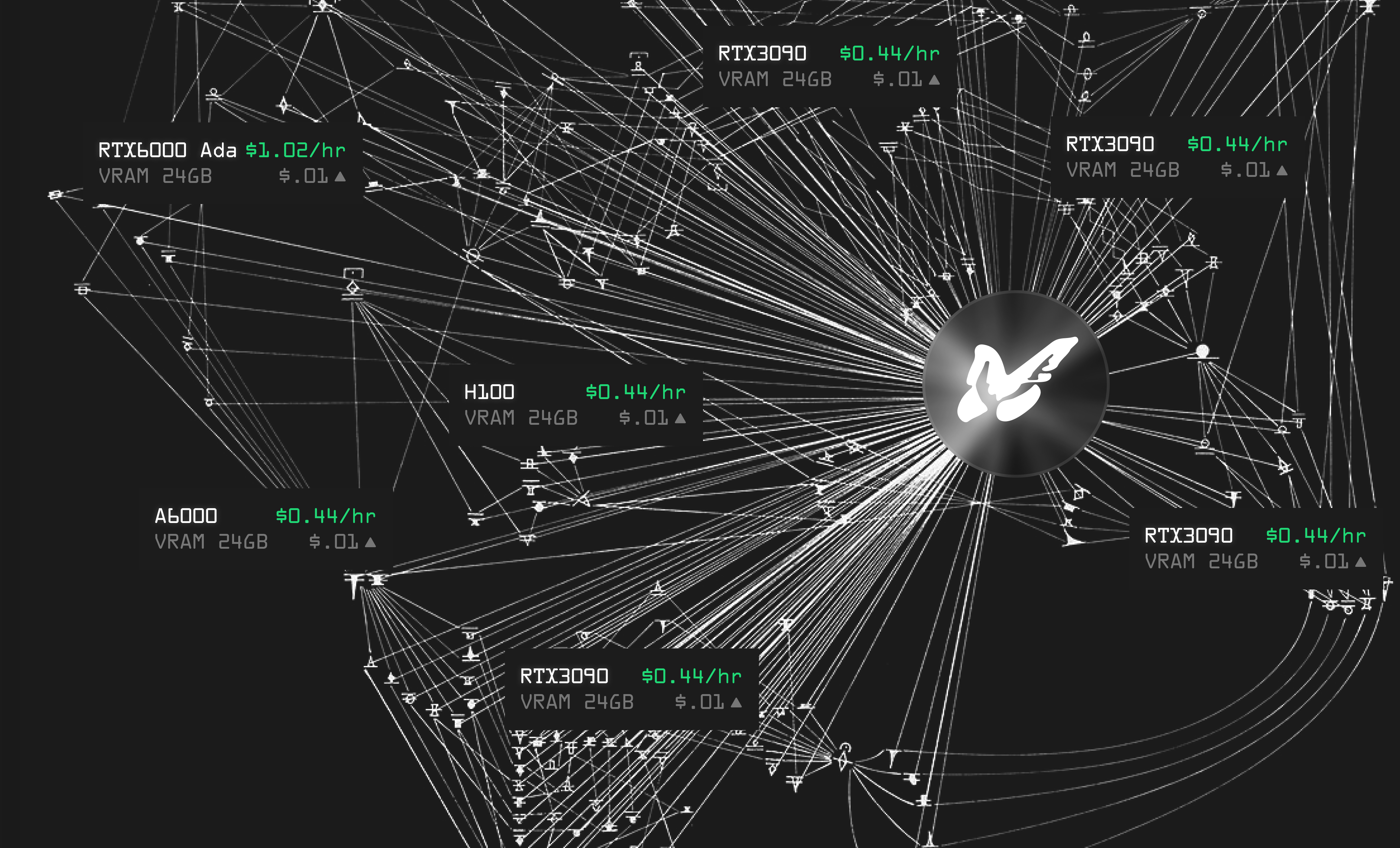
Advanced GPU Scheduling with Parallax: Parallax transforms pools of heterogeneous GPUs into efficient decentralized inference networks. Its advanced scheduling decomposes model allocation and request-time GPU pipeline selection, consistently reducing latency and increasing throughput—demonstrating the viability of volunteer compute for large-scale LLM inference.
Lamina’s attention offloading is a standout example. By routing attention computations (the most resource-intensive part of transformer models) to lower-cost consumer GPUs while reserving premium accelerators for other tasks, Lamina achieves up to 12.1x higher throughput per dollar than legacy setups (source). This fine-grained allocation ensures that each hardware type is used where it delivers maximum value.
The Splitwise technique takes this further by dividing LLM inference into two distinct phases, prompt computation and token generation, and assigning each phase to machines optimized for those specific workloads. This separation enables 1.4x higher throughput at 20% lower cost than monolithic designs (source). The upshot: more efficient use of distributed resources without compromising performance.
The Rise of Decentralized Inference Platforms
A new generation of platforms is operationalizing these advances at scale. For instance, Parallax transforms pools of heterogeneous GPUs into efficient inference networks through advanced scheduling and request-time pipeline selection (source). By decomposing model allocation and optimizing which GPUs handle which requests in real time, Parallax consistently reduces latency and increases throughput, even when relying on volunteer or non-dedicated hardware.
This shift isn’t just theoretical; it’s already delivering tangible results across industries from healthcare analytics to creative content generation. As more contributors join decentralized GPU networks and as scheduling algorithms mature, we’re seeing the barriers to scalable AI fall away, replaced by an open marketplace where compute is both abundant and affordable.
What makes decentralized LLM inference networks especially compelling is their ability to break the stranglehold of centralized cloud providers while maintaining robust performance. By distributing workloads across a dynamic, global network of GPUs, these platforms sidestep the capital intensity and vendor lock-in that have long defined AI deployment. This not only drives down costs but also introduces greater resilience and flexibility, as compute resources can be reallocated or scaled up in response to real-time demand.
Crucially, the economic incentives underlying decentralized AI infrastructure are reshaping participation in the ecosystem. Through crypto-powered reward systems, sometimes referred to as “AI mining”: individuals and organizations can monetize their spare GPU capacity. This model aligns with DePIN principles by transforming passive hardware into active revenue streams, while also ensuring that networks remain sufficiently provisioned to handle surges in inference demand.
Beyond Cost: Security, Privacy, and Ecosystem Impact
While cost reduction is a headline benefit, decentralized LLM inference also addresses critical concerns around data privacy and security. By allowing sensitive computations to be distributed or even kept on-premises, organizations can avoid sharing proprietary data with third-party cloud vendors. This is particularly attractive for sectors like healthcare and finance, where regulatory compliance and confidentiality are paramount.
Furthermore, the open-source ethos pervading many decentralized platforms encourages transparency and community-driven innovation. Projects like DecentralGPT are pushing the boundaries by combining distributed compute with open governance models, helping ensure that advances in AI infrastructure remain accessible rather than siloed within tech giants.
Top Benefits of Decentralized LLM Inference for Enterprises
-
Significant Cost Reduction: Decentralized LLM inference networks like Hyperbolic leverage global pools of underutilized GPUs, enabling enterprises to cut AI compute costs by up to 70–75% compared to traditional cloud providers.
-
Enhanced Resource Utilization: By aggregating idle GPU resources worldwide, platforms such as Hyperbolic and Parallax maximize hardware efficiency, ensuring high-performance inference without the need for costly, dedicated clusters.
-

Scalable and Flexible Infrastructure: Decentralized networks can dynamically scale to meet enterprise demand, utilizing heterogeneous GPU resources to handle varying workloads efficiently, as demonstrated by systems like Parallax and Lamina.
-

Optimized Inference Performance: Innovations like attention offloading and phase splitting (used by Lamina and Splitwise) allocate tasks to the most suitable hardware, achieving up to 12.1x higher throughput per cost and reducing latency for large-scale applications.
-

Reduced Vendor Lock-In: Decentralized approaches give enterprises the freedom to avoid dependence on a single cloud provider, fostering greater control over infrastructure choices and potentially enhancing security and compliance.
The Road Ahead: Challenges and Opportunities
Despite these advances, several challenges remain on the path to mainstream adoption. Ensuring consistent quality of service across heterogeneous hardware pools requires sophisticated scheduling algorithms and fault tolerance mechanisms. Network latency, especially when GPUs are geographically dispersed, can impact real-time applications unless mitigated by smart routing or edge deployments. Finally, establishing robust security protocols for distributed workloads will be essential as these networks scale.
Yet the momentum is undeniable. As more developers contribute to open-source projects and as tokenized incentive mechanisms mature, expect further innovation in how AI compute is provisioned and monetized globally. The convergence of blockchain AI infrastructure with distributed GPU networks signals a new era where scalable intelligence becomes not just cheaper but fundamentally more accessible, and more aligned with user needs rather than vendor interests.
For those building next-generation applications or seeking to optimize enterprise AI spend, monitoring developments in decentralized LLM inference, AI mining rewards, and DePIN for AI will be critical over the coming year. The opportunity is clear: unlock powerful language models at a fraction of legacy costs while participating in a more open, resilient computational ecosystem.



